发送反馈
05 向量数据库
最后更新时间 (CST):2023-10-25 05:25:01 +0800
提示 :文章中 「向量」 与 「矢量」 意义相同,这里统一使用 「向量」。
AI 应用程序设计师的武器库中的另一个重要新工具是向量数据库,这是一个之前没有受到太多关注的类别。
这可能是因为数据库从计算机的早期就存在,并且它们是许多应用程序的众所周知的基础。
但是,数据库的熟悉和长寿掩盖了一个事实,即它们随着新类型应用的需求在这段时间内发生了相当大的演变。
如今,数据库再次变革,以满足机器学习对向量数据库的需求。
传统数据库 vs 向量数据库
最初,数据库主要是关于填满行和列的整洁表格。它们在桌面和早期企业时代的应用中表现良好,并使得像 Oracle 这样的公司成为科技巨头。
随着云计算和大数据的兴起,出现了像 Cassandra 或 MongoDB 这样的 NoSQL 数据库,它们使用 JSON 文档,可以比传统数据库更好地适应特定类型的工作负载,这些工作负载随着亿万人口的上网而出现。
向量数据库是数据库家族的最新演变之一。它们存储向量嵌入——专为人工智能和机器学习应用而设计的关键数据。
向量嵌入只是数据的数值表示。它们可以是图像、视频或 NLP 中使用的单词/句子。
某些数据集具有更结构化的列和数据值,而其他数据集可能包含更多无结构化的文本,例如整个法律文件、小说或在线文章。
但是,任何数据都可以转换为向量,无论是整个文档还是仅几个单词或图像中的像素。基本上,任何其他对象都可以轻松转换为向量。甚至数值数据也可以转换为向量。
在 LLMs 和 智能体 的世界中,向量数据库是隐藏的 Workhorses
。它们使得按语义相似性对嵌入进行排序、存储和搜索成为可能,该相似性由它们在向量空间中的接近程度表示。
当涉及自然语言查询时,这是一种有用的超能力。这意味着查询不需要完全匹配才能被视为匹配。
传统数据库对所有内容提供精确匹配,比如「寻找住在 Springfield Road 125号 的 John Nash 的记录并给我他的最后订单」。
然而,向量数据库使用相似性度量来查找与查询接近的任何向量。为此,它们使用了用于搜索的近似最近邻(ANN
)搜索算法,如产品量化、分层可导航小世界或随机投影。
基本上,这些算法压缩了原始向量,使查询过程更快。它们还可以进行其他类型的相似性比较,如欧氏距离和点积比较,以确定最有用的结果。
在传统数据库(如 Postgres)中,我们通常查询的是与查询完全匹配的行。
在向量数据库中,数据库后端应用这些相似性度量来找到与查询最相似的向量。它的各种算法被组合成一个流水线,可以快速检索查询向量的邻居。
由于向量数据库提供的是近似结果,而不是精确结果,我们面临的主要权衡是总体准确性与速度之间的平衡。如果我们需要更高的准确性,查询可能会变慢,所以准确性和速度之间总会存在权衡。
然而,设计良好的向量数据库可以提供高质量准确性的快速搜索。
这在现实世界中如何体现呢?所有这些相似性搜索可以让您轻松找到与某人提出的问题非常相似的问题,即使他们用不同的语言提问。
这意味着应用程序设计师可以返回预先准备好的回答,而不必等待来自云端 LLM API 的答案,从而节省往返时间和成本。
这些嵌入就像是意义紧凑的快照,在推理期间可以作为对新数据的过滤器。
如果您只是通过精确匹配从数据库中提取答案,那么在问题的范围高度结构化和有限的情况下,这种方法是有效的,但当问题的范围几乎无限时,这种方法很快就会变得不可行。
向量数据库还可以用于存储我们作为人类处理的模糊知识。
想象一下,一个能够理解您提出的问题并查找以前回答中类似代码的配对编码 LLM,为解决相同问题提供了多次的快捷方式。
让我们来看一个例子。一个用户可能会问一个LLM:「随着年龄增长,恢复头发的最佳方法是什么?」 另一个用户可能会问:「如何让我的头发重新长出来?」 还有一个用户可能会问:「如何停止脱发?」 有成千上万种问这个问题的方式,而向量数据库可以理解这些问题之间的语义相似性,并在几秒钟内给出答案。
它还可以用于应用程序的长期记忆。您可以指示 LLM 查找它过去给出的答案或对话的状态,以便它不是从零开始,并可以有连贯性地继续。
另一个很好的例子来自开发者 Max Woolf 的博客 ,他写道:
我被委托为
Tasty 品牌创建一个基于 ChatGPT 的聊天机器人(后来在 Tasty iOS 应用中发布为
Botatouille ),可以与用户聊天并提供相关的食谱。
源食谱被转换为 Embeddings 并保存在向量存储中,例如:
如果用户要求「健康食品」,则将查询转换为 Embeddings,并执行近似最近邻搜索以找到与 Embeddings 查询类似的食谱,然后将其作为附加上下文提供给 ChatGPT,然后可以显示给用户。
这种方法更常被称为
「retrieval-augmented generation」.(检索-增强生成:
RAG )。
—— 摘自 Max Woolf 的博客
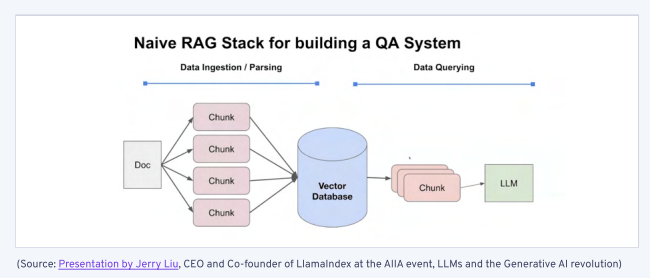
我们可以在 LlamaIndex 文档中找到一个简单的 RAG 示例。它基本上是一个两阶段的过程:
索引:设置知识库并填充数据
查询:从数据库中检索知识,帮助 LLM 回答问题或执行任务
资料来源:LlamaIndex 首席执行官兼联合创始人 Jerry Liu 在 AIIA 活动《LLMs 和生成式人工智能革命》 上的演讲
向量数据库
检索增强可以通过向量数据库本身或特征存储(如 Fennel 或 Feast )提供,以运行更复杂的查询并确保我们拥有最新的信息。
例如,对一个类似 Uber 的应用程序询问 LLM 「我的司机在哪里」 不能从静态答案中获取。它需要实时更新,因为司机在移动。
但是关于特征存储的全面概述超出了本文档的范围,读者应该参考我们《2022年的 AI 基础设施生态系统报告》 以获取更多信息。
基本上,对于 LLMs 来说,向量数据库可以更好地理解数据之间的关系并保持长期记忆。在 LLMs 中,上下文窗口通常很短。
截至2023年夏季,最长的上下文窗口为10万个 token,尽管有一些具有更大上下文窗口的开源模型,并且研究人员正在研究如何扩展它们的技巧。
但即使有这些长的上下文窗口,研究人员发现当前模型局限性是关注整个上下文的能力,而是发现它们倾向于关注开头和结尾,并在中间出现大幅下降。
斯坦福大学、加州大学伯克利分校和 Samaya AI 的研究人员撰写的名为《Lost in the Middle》 的论文,告诉您关于当今最先进模型中当前上下文窗口的限制几乎所有您需要知道的内容。
一百万个 token 听起来可能很多,但在加载大量文档时它们很快就会用尽,而且一个单独的文档可能无法适应该上下文窗口。
这有点像计算机的早期,内存非常稀缺,程序员不得不使用许多技巧在有限的内存中进行数据交换。
在向量数据库中,数据根据它们的几何特征进行排序和存储。每个项目都通过其在空间中的坐标和定义它的其他属性来进行标识。
由向量数据库支持的地理信息系统 (GIS)应用程序可能是跟踪城镇网格和河流、高速公路、小路和重要地标的蜿蜒线条之间众多相似之处的更好选择,将它们按照相似性聚合进行排序。
这将使某人能够探索彼此相邻、大小或形状相似的所有建筑物,如果这些信息在单元格中没有硬编码,就几乎无法在传统数据库中实现。
另一个例子是在法律文件中搜索包含类似但不完全相同措辞的段落,这些段落涉及协议可能在法庭冲突时进行诉讼的司法管辖区。
这将使法律团队找到可能影响他们必须争取案件的地方的非标准段落,如果这些司法管辖区在地理上分散,并且不得不同时在洛杉矶、纽约和伦敦之间进行多个法律战斗,那么这可能会变得非常昂贵。
当涉及到 Agent 和 Centaur
应用程序时,向量数据库充当应用程序的长期记忆,并用于以后的搜索和排序中加载大量数据的方式。
如果您想加载过去一年的所有地区法院的案例,以便构建一个问答机器人,您可能会在将所有向量加载到内存中时遇到困难,例如通过 NumPy 处理的 CSV 文件。
为了处理这些大量的数据,Agent 可能会从向量数据库中获取它们,或者如果它们是新的,则从 URL、外部数据库或文件系统中加载。
通常,Agent 编码人员会编写自己的文档管理抽象,但他们也可能使用类似 LangChain 或 LlamaIndex 的工具来处理文档并将其分解为适合上下文窗口的可管理的数据块。
除非它们非常小,否则这些数据块会在途中被切分,以确保 LLM 可以处理它们和它们的有限上下文窗口,并利用相似性搜索。
在 LangChain 中,您可以使用 「DirectoryLoader 」 将文档加载到内存中,并使用 Document Transformer 中的 「RecursiveCharacterTextSplitter 」将其分解为可用的数据块。
该函数使用默认块大小为 1000 个字符对文档进行字符级拆分。它还包括20个字符的块重叠。
块重叠可能一开始看起来有些奇怪,但它基本上确保在不同块之间存在完全匹配的文本,以确保完美的连续性并最大限度地减少边界处丢失意义的风险。
将数据放入向量数据库通常遵循以下模式。
数据被分解成可管理的块
然后转换为向量 Embeddings
数据库对 Embeddings 进行索引以实现快速检索。
当用户查询数据库时,它会计算块向量之间的相似度指标并返回匹配结果。
为了进一步加快查询速度,向量数据库预先计算了向量之间的某些常见相似性。
Agent 编写人员可能会构建自己的接口框架,以加快或预先计算他们的应用程序中预计会经常使用的相似性类型。
例如,如果应用程序是股票图像生成器,它可能具有一系列先前经过高度评价和成功的提示。
应用程序可能根据用户的提示返回一些图像,或者可能返回已经与该查询密切匹配的图像,而不是从头开始生成图像,这样可以节省 GPU 时间。
在 AIIA 看来,定制的向量数据库(如 Pinecone 、Activeloop 、ChromaDB 或 Weaviate )与将向量功能添加到现有数据库(如 Postgres 的 Pgvector 或 MongoDB’s Atlas Vector Search )相比,其主要驱动因素之一将是特性、性能、易用性、可扩展性和安全性等古老问题。
现有的数据库在可扩展性和安全性方面有优势,因为他们已经处理过这些问题多年,但在向量应用程序的发展阶段,很难判断他们的传统架构在添加向量功能时是有利还是有弊。
长期来看,专门为向量设计的向量数据库会占有优势,还是更明智地将向量功能添加到现有的技术栈中,这样你就可以在一个地方查询传统的基于行的结果和向量?时间会告诉我们答案。
无论如何,我们预计为互联网大规模的 Agent 应用程序或企业提供服务的所有向量数据库都需要具备强大的性能和容错能力。
这是一个众所周知的问题,并不是我们希望在机器学习时代重新发明的东西。
相反,这些公司已经倚重于经过验证和可靠的解决方案,以使数据库更大、更具弹性,尤其是:
Sharding(分片):意味着将数据分布在多个节点上。有许多将数据分片的方法正在被应用于向量数据库,例如按照共享相似模式的数据集群进行分片。这使得查询很少需要与两个不同的节点通信,这可能会对查询性能造成影响。Replication(复制):意味着在不同的节点上创建数据的多个副本,这样一个节点的停机并不意味着所有数据都停机。即使某个节点失败,其他节点仍然能够回答查询。数据库有两种历史一致性模型:强一致性和最终一致性。
最终一致性允许在不同数据副本之间存在临时的不一致性。这通常意味着大大提高了可用性并降低了延迟,但如果冲突的更改无法纠正,这也可能意味着以后的数据冲突甚至数据丢失。
第二种方法,强一致性,意味着在写操作被认为完成之前,所有数据副本都必须被更新。这确保数据始终保持一致,但可能会增加延迟。
Pinecone 和 Atlas for Mongo 使用最终一致性方法和 NoSQL 风格的数据库(例如 Cassandra )。
在最终一致性的情况下,数据库遵循仲裁的概念,您可以设置需要拥有相同数据副本的节点数量,然后才能回复答案。
更高的仲裁数意味着更好的一致性,而较低的仲裁数则意味着更低的延迟。像 Cassandra 这样的 NoSQL 数据库提供了高写入吞吐量和非常低的延迟。
在 Cassandra 中,仲裁一致性通常是因为大多数副本节点(n/2 + 1)必须响应查询。仲裁过程会检查大多数副本,以给出相同的答案。
例如,如果管理员在2个数据中心设置了复制因子为 3,则会有 6 个副本,在这种情况下,多数是 4 个。
最终一致性适用于日志数据、时间序列数据、分析工作负载和很多机器学习工作负载。
另一方面,像 Oracle 、MySQL 和 Postgres 这样的传统行列式数据库提供非常高的一致性,因此它们更适用于要求极高准确性的工作负载,例如支付交易和银行数据。
Agent 设计人员开发的应用程序的类型将使他们倾向于选择其中一种或多种类型的数据库。
设计用于医疗事务的应用程序需要更高水平的准确性和一致性,而回答问题和进行公共公司研究的应用程序则不需要这么高的准确性和一致性。
向量数据库领域正在快速发展,但目前的主要参与者如下:
产品
描述
Pinecone Pinecone 由于其基于 SaaS 云平台的方法、易于入门的特点以及出色的性能和可扩展性,Pinecone 是市场上最重要的参与者之一。
Pgvector Pgvector 是 Postgres 的开源附加组件,由于开发人员对 Postgres 的熟悉以及能够在一个地方进行精确查询和向量查询的能力,它在开发人员中越来越受欢迎。
Activeloop Activeloop 是一个独特的解决方案,它可以作为一个数据湖(data lake),存储从文档到视频到图像等各种数据,并且还可以作为嵌入式实例存储 Embeddings 向量和元数据。
Weaviate Weaviate 提供 SaaS 服务,也可以作为 Docker 容器的安装程序,在本地、云端甚至作为嵌入式实例使用。它内置了多个经过优化的预设检索模块,适用于各种用例,如问答。
MongoDB’s Atlas MongoDB 的 Atlas 向量搜索是一个公开预览版(在撰写本文时),它通过MongoDB 云服务提供。它允许在一个完全托管的平台上同时进行传统 NoSQL 工作负载和向量搜索。
Vespa Vespa 是另一个开源产品,提供无状态容器前端来处理数据和查询,而这些查询由提供最终一致性的内容集群支持。
DataStax DataStax 提供的向量数据库可以在 Cassandra 数据库或 Astra 数据库中工作,Astra 数据库是符合 Cassandra 标准的数据库,在云端部署更加简化。与 MongoDB 等类似的产品一样,它旨在将 NoSQL 和向量搜索统一在一个平台上。
Milvus Milvus 是一个于2019年发布的开源产品,用于存储、索引和管理大规模的嵌入向量,以支持机器学习。它支持在 Kubernetes 上进行集群部署,实现水平扩展。
FeatureBase FeatureBase 是一个内存中的分析和向量引擎,支持 SQL 查询、实时更新和快速的点查询,适用于机器学习工作负载。
提示 :阅读这里查阅部分向量数据库「功能对比
[1]
[2]
[3]
发送反馈