Embedding
什么是 Embedding?
「Embedding」是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。embedding 向量通常是一个由实数构成的向量,它将输入的数据表示成一个连续的数值空间中的点。
词向量
从字面本身计算语义相关性是不够的。
- 不同字,同义:「快乐」vs.「高兴」
- 同字,不同义:「上马」vs.「马上」
所以我们需要一种方法,能够有效计算词与词之间的关系,词向量(Word Embedding)应运而生。
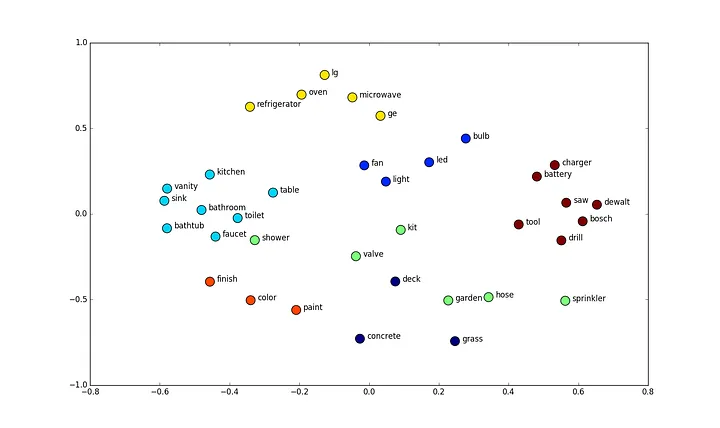
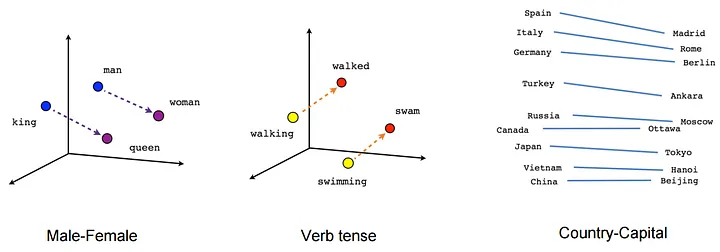
词向量的基本原理
用一个词上下文窗口表示它自身
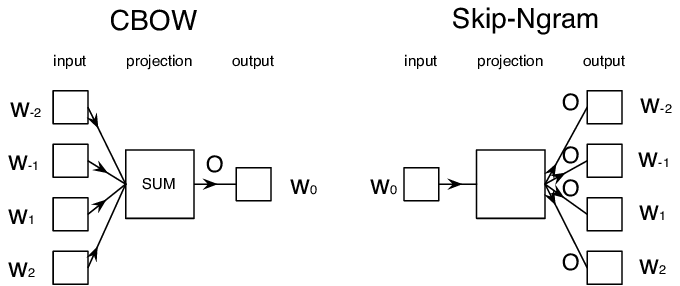
词向量的不足
- 同一个词在不同上下文中语义不同:我从「马上」下来 vs. 我「马上」下来
关于词向量,更多内容参考:
基于整个句子,表示句中每个词,那么同时我们也就表示了整个句子
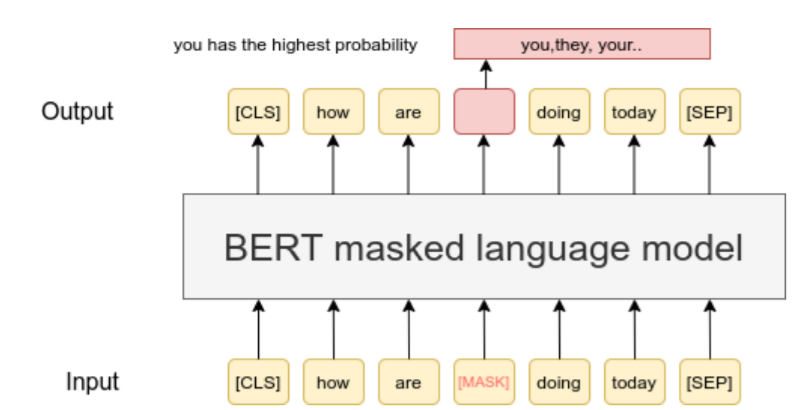
所以,句子、篇章都可以向量化
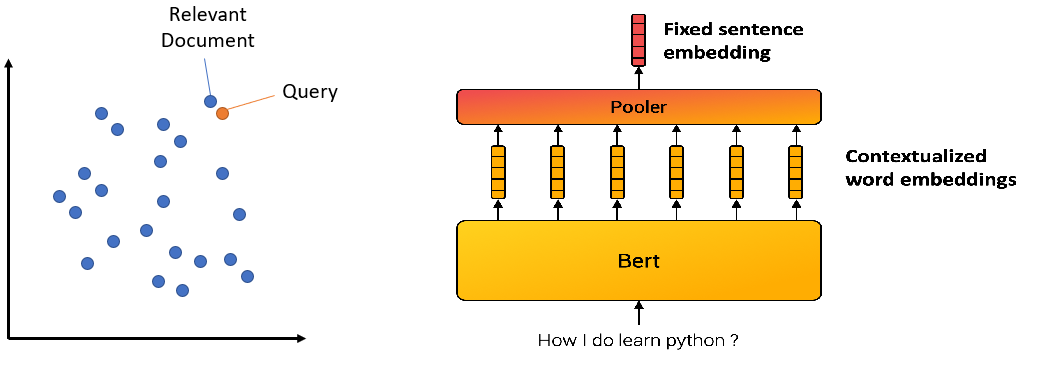
Sentence Transformer
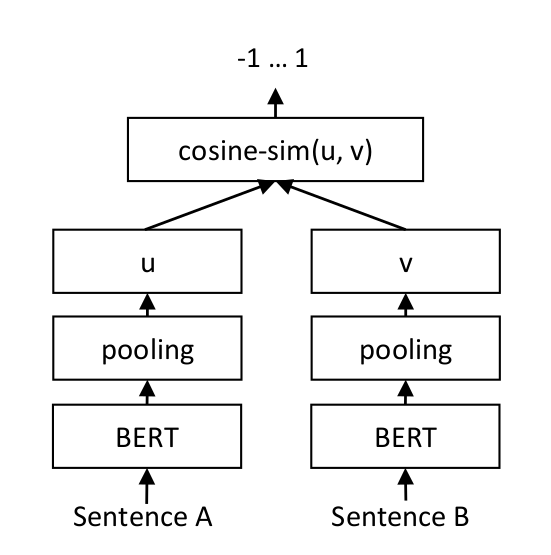
向量相似度计算
[1]:
import numpy as np
from numpy import dot
from numpy.linalg import norm
from langchain.embeddings import OpenAIEmbeddings
def cos_sim(a, b):
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
x = np.asarray(a)-np.asarray(b)
return norm(x)
model = OpenAIEmbeddings(model='text-embedding-ada-002')
query = "国际争端"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = model.embed_query(query)
doc_vecs = model.embed_documents(documents)
print("Cosine distance:") # 越大越相似
print(cos_sim(query_vec, query_vec))
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print("\nEuclidean distance:") # 越小越相似
print(l2(query_vec, query_vec))
for vec in doc_vecs:
print(l2(query_vec, vec))
[ ]:
Cosine distance: 1.0 0.8226018711360235 0.829977812402014 0.7983723967257063 0.7671380839706725 0.7934757098362577 Euclidean distance: 0.0 0.5956477631351883 0.5831332396596614 0.6350237842385019 0.6824396178847291 0.6426885562443797
基于相似度聚类
[2]:
from langchain.embeddings import OpenAIEmbeddings
from sklearn.cluster import KMeans, DBSCAN
import numpy as np
texts = [
"这个多少钱",
"啥价",
"给我报个价",
"我要红色的",
"不要了",
"算了",
"来红的吧",
"作罢",
"价格介绍一下",
"红的这个给我吧"
]
model = OpenAIEmbeddings(model='text-embedding-ada-002')
X = []
for t in texts:
embedding = model.embed_query(t)
X.append(embedding)
# clusters = KMeans(n_clusters=3, random_state=42, n_init="auto").fit(X)
clusters = DBSCAN(eps=0.55, min_samples=2).fit(X)
for i, t in enumerate(texts):
print("{}\t{}".format(clusters.labels_[i], t))
[ ]:
0 这个多少钱 0 啥价 0 给我报个价 1 我要红色的 -1 不要了 -1 算了 1 来红的吧 -1 作罢 0 价格介绍一下 1 红的这个给我吧
尝试本地部署
[$]:
!pip install sentence_transformers
[3]:
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-zh-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
[4]:
query = "国际争端"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = model.embed_query(query)
doc_vecs = model.embed_documents(documents)
print("Cosine distance:") # 越大越相似
print(cos_sim(query_vec, query_vec))
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
[ ]:
Cosine distance: 1.0 0.39085908636919475 0.31848764875846713 0.28801350328358377 0.2598757213201276 0.2611598107519106
关于向量相似度计算,更多内容参考:
