Semantic Kernel
什么是 Semantic Kernel ?
为了帮助开发人员在 AI 插件之上构建自己的 Copilot 体验,微软发布了 Semantic Kernel,这是一个轻量级开源 SDK,可让您编排 AI 插件。 借助 Semantic Kernel,您可以在自己的应用程序中利用与 Microsoft 365 Copilot 和 Bing 相同的 AI 编排模式,同时仍然利用现有的开发技能和投入。
SK 的开发进展
Semantic Kernel 现在还是未正式发版状态。1.0.0 版预计今年底发布。
- C# 版最成熟,已开始
1.0.0-beta1 - Python 版还在
dev状态,但可用 - Java 版
alpha阶段 - TypeScript 版发展缓慢,可能已经放弃了
文档写得特别好,但追不上代码更新速度:
SK 的生态位
与 LangChain 完全重叠。微软将此技术栈命名为 「Copilot Stack」。
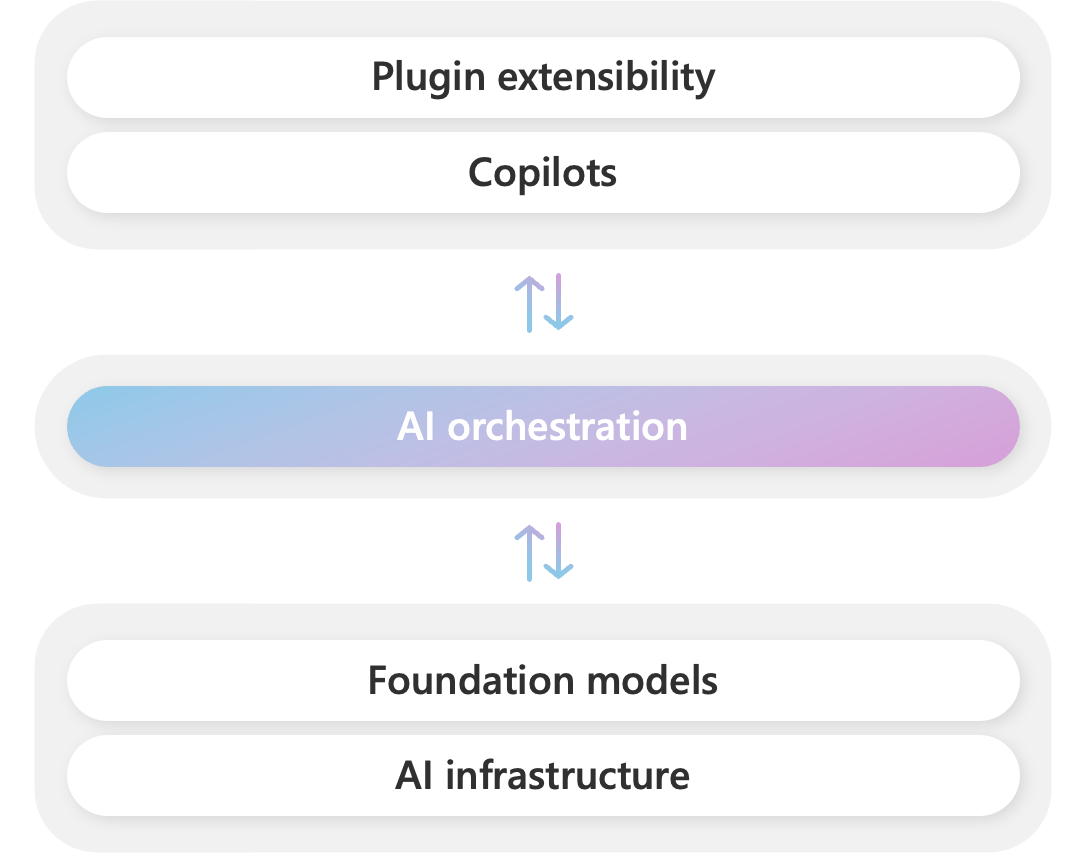
Plugin extensibility: 插件扩展Copilots: AI 助手(副驾驶),例如 GitHub Copilot、Office 365 Copilot、Windows CopilotAI orchestration: AI 编排,SK 就在这里Foundation models: 基础大模型,例如 GPT-4AI infrastructure: AI 基础设施,例如 PyTorch、GPU
SK 基础架构
Semantic Kernel 用 Kernel 命名,是因为它确实像个操作系统 kernel,做核心资源调配,各种资源都可以挂在它之上。
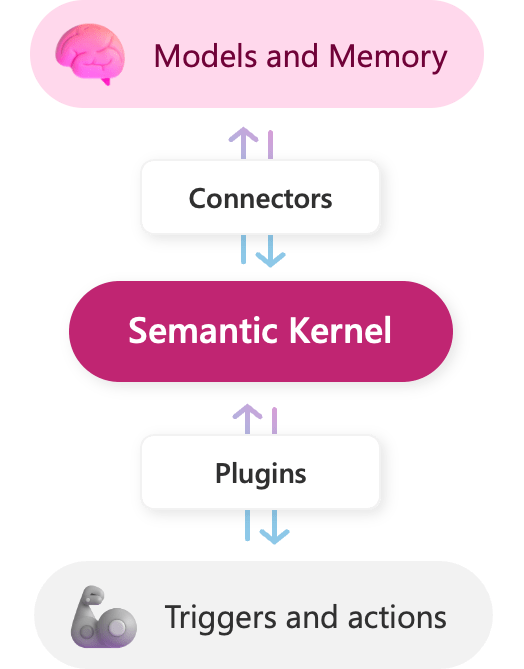
Models and Memory: 和 LangChain 的概念相同,类比为大脑Connectors: 用来连接各种外部服务,类似驱动程序Plugins: 用来连接内部技能Triggers and actions: 外部系统的触发器和动作,类比为四肢
SK 对集成第三方能力的态度是不希望放在自己的核心代码库中,像操作系统一样,它只提供最基础的能力,其它的都是外部维护,按需安装。 参考 这里。
使用案例
# 安装最新版本 !pip install semantic-kernel
在项目目录创建 .env 文件,添加以下内容:
# .env
OPENAI_API_KEY=""
OPENAI_API_BASE=""
AZURE_OPENAI_DEPLOYMENT_NAME=""
AZURE_OPENAI_ENDPOINT=""
AZURE_OPENAI_API_KEY=""
Hello World
这是一个简单示例。
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
import os
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 创建 semantic kernel
kernel = sk.Kernel()
# 配置 OpenAI 服务
api_key = os.getenv('OPENAI_API_KEY')
endpoint = os.getenv('OPENAI_API_BASE')
model = OpenAIChatCompletion("gpt-3.5-turbo", api_key, endpoint=endpoint)
# 把 LLM 服务加入 kernel
# 可以加多个。第一个加入的会被默认使用,非默认的要被指定使用
kernel.add_text_completion_service("my-gpt3", model)
<semantic_kernel.kernel.Kernel at 0x7f6990476b10>
执行讲笑话的 prompt
# 定义 semantic function
tell_joke_about = kernel.create_semantic_function("给我讲个关于{{$input}}的笑话吧")
# 看结果
print(tell_joke_about("Hello world"))
好的,这是一个关于Hello world的笑话: 程序员A对程序员B说:“我刚刚写了一个非常简单的Hello world程序。” 程序员B问:“真的吗?那你能不能把它运行起来?” 程序员A回答:“当然可以!” 程序员B疑惑地问:“那你为什么不运行它呢?” 程序员A笑着说:“因为我还没写完它的文档。”
站在操作系统的角度来理解 SK:
- 启动操作系统:
kernel = sk.Kernel() - 安装驱动程序:
kernel.add_xxx_service() - 安装应用程序:
func = kernel.create_semantic_function() - 运行应用程序:
func()
基于 SK 开发的主要工作是写「应用程序」,也就是 Plugins。
Plugins
简单说,plugin 就是一组函数的集合。它可以包含两种函数:
Semantic Functions- 语义函数,本质是 Prompt EngineeringNative Functions- 原生函数,类似 OpenAI 的 Function Calling
值得一提的是,SK 的 plugin 会和 ChatGPT、Bing、Microsoft 365 通用。
很快用 SK 写的 plugin 就可以在这些平台上无缝使用了。这些平台上的 plugin 也可以通过 SK 被调用。
1.0.0 发布才能清理干净,两者是一回事。
Semantic Functions
Semantic Functions 是纯用数据(prompt + 描述)定义的,不需要编写任何代码。所以它与编程语言无关,可以被任何编程语言调用。
一个典型的 Semantic Function 包含两个文件:
skprompt.txt: 存放 prompt,可以包含参数,还可以调用其它函数config.json: 存放描述,包括函数功能,参数的数据类型,以及调用大模型时的参数
举例:把 LangChain 「生成 Linux 命令」的例子用 SK 实现。
准备 skprompt.txt:
准备 config.json:
上面两个文件都在 sk_samples/SamplePlugin/GenerateCommand 目录下。
# 加载 semantic function。注意目录结构
functions = kernel.import_semantic_skill_from_directory("./sk_samples/", "SamplePlugin")
cli = functions["GenerateCommand"]
# 看结果
print(cli("将系统日期设为2023-04-01"))
{
"command": "date",
"arguments": {
"-s": "2023-04-01"
}
}
官方提供了大量的 Semantic Functions 可以参考
Semantic Kernel Tools 是个 VS Code 的插件,在 VS Code 里可以直接创建和调试 Semantic Function。
Native Functions
使用编程语言写的函数,如果用 SK 的 Native Function 方式定义,就能纳入到 SK 的编排体系,可以被 Planner、其它 plugin 调用。
下面,写一个过滤有害 Linux 命令的函数,和 GenerateCommand 组合使用。
这个函数名是 harmful_command。如果输入的命令是有害的,就返回
true
,否则返回
false
。
它也要放到目录结构中,在 sk_samples/SamplePlugin/SamplePlugin.py 里加入。
from sk_samples.SamplePlugin.SamplePlugin import SamplePlugin
# 加载 semantic function
functions = kernel.import_semantic_skill_from_directory(
"./sk_samples/", "SamplePlugin")
cli = functions["GenerateCommand"]
# 加载 native function
functions = kernel.import_skill(SamplePlugin(), "SamplePlugin")
harmful_command = functions["harmful_command"]
# 看结果
command = cli("删除根目录下所有文件")
print(command) # 这个 command 其实是 SKContext 类型
print(harmful_command(context=command)) # 所以要传参给 context
{
"command": "rm",
"arguments": {
"-rf": "/"
}
}
true
用 SKContext 实现多参数 Functions
如果 Function 都只有一个参数,那么只要把参数定义为 {{$input}},就可以按前面的例子来使用,比较直观。{{$input}} 会默认被赋值。
多参数时,就不能用默认机制了,需要定义
SKContext
类型的变量。
from sk_samples.SamplePlugin.SamplePlugin import SamplePlugin # 加载 native function functions = kernel.import_skill(SamplePlugin(), "SamplePlugin") add = functions["add"] # 看结果 context = kernel.create_new_context() context["number1"] = 1024 context["number2"] = 65536 total = add(context=context) print(total)
66560.0
内置 Plugins
SK 内置了一些好用的 plugin,但因为历史原因,它们被命名为 skill……
加载方法:
from semantic_kernel.core_skills import [SkillName]
包括:
ConversationSummarySkill- 生成对话的摘要FileIOSkill- 读写文件HttpSkill- 发出 HTTP 请求,支持 GET、POST、PUT 和 DELETEMathSkill- 加法和减法计算TextMemorySkill- 保存文本到 memory 中,可以对其做向量检索TextSkill- 把文本全部转为大写或小写,去掉头尾的空格(trim)TimeSkill- 获取当前时间及用多种格式获取时间参数WaitSkill- 等待指定的时间WebSearchEngineSkill- 在互联网上搜索给定的文本
Memory
SK 的 memory 使用说明:
kernel.add_text_embedding_generation_service():添加一个文本向量生成服务kernel.register_memory_store():注册一个 memory store,可以是内存、文件、向量数据库等kernel.memory.save_information_async():保存信息到 memory storekernel.memory.search_async():搜索信息
使用 SK 的 README.md 做数据,使用内存作为 memory store,演示下基于文档对话。
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion, OpenAITextEmbedding
import os
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 创建 semantic kernel
kernel = sk.Kernel()
# 配置 OpenAI 服务
api_key = os.getenv('OPENAI_API_KEY')
endpoint = os.getenv('OPENAI_API_BASE')
model = OpenAIChatCompletion("gpt-3.5-turbo", api_key, endpoint=endpoint)
# 把 LLM 服务加入 kernel
# 可以加多个。第一个加入的会被默认使用,非默认的要被指定使用
kernel.add_text_completion_service("my-gpt3", model)
# 添加 embedding 服务
kernel.add_text_embedding_generation_service(
"ada", OpenAITextEmbedding("text-embedding-ada-002", api_key, endpoint=endpoint))
<semantic_kernel.kernel.Kernel at 0x1154f5650>
from semantic_kernel.text import split_markdown_lines
# 使用内存做 memory store
kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
# 读取文件内容
with open('SK.md', 'r') as f:
# with open('sk_samples/SamplePlugin/SamplePlugin.py', 'r') as f:
content = f.read()
# 将文件内容分片,单片最大 100 token(注意:SK 的 text split 功能目前对中文支持不如对英文支持得好)
lines = split_markdown_lines(content, 100)
# 将分片后的内容,存入内存
for index, line in enumerate(lines):
await kernel.memory.save_information_async("sk", id=index, text=line)
result = await kernel.memory.search_async("sk", "License 协议?")
print(result[0].text)
microsoft.com/codeofconduct/). For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or contact [[email protected]](mailto:[email protected]) with any additional questions or comments. ## License Copyright (c) Microsoft Corporation. All rights reserved. Licensed under the [MIT](LICENSE) license.
Pipeline (vs Chain)
SK 更想用 Pipeline 来描述 LangChain 中 chain 的概念,大概因为 pipeline 这个词更符合操作系统吧。但 chain 这个名词影响力太大,所以 SK 时不时也会用它。
但是,SK 没有在代码里定义什么是 pipeline,它并不是一个类,或者函数什么的。它是贯彻整个 kernel 的一个概念。 当一个 kernel 添加了 LLM、memory、functions,我们写下的 functions 之间的组合调用,就是个 pipeline 了。 如果需要多条 pipeline,就定义多个 kernel。
现在用 pipeline 思想把对话式搜索 SK 的 README.md 功能做完整。
在自定义的 Semantic Function 中,嵌套调用内置的 TextMemorySkill。
# 导入内置的 `TextMemorySkill`。主要使用它的 `recall()`
kernel.import_skill(sk.core_skills.TextMemorySkill())
# 直接在代码里创建 semantic function。真实工程不建议这么做
# 里面调用了 `recall()`
sk_prompt = """
基于下面的背景信息回答问题。如果背景信息为空,或者和问题不相关,请回答"我不知道"。
[背景信息开始]
{{recall $input}}
[背景信息结束]
问题:{{$input}}
回答:
"""
ask = kernel.create_semantic_function(sk_prompt)
# 提问
context = kernel.create_new_context()
context[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "sk"
context[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = 0.8
context["input"] = "怎么使用 Semantic Kernel"
result = ask(context=context)
print(result)
使用Semantic Kernel的最快方法是使用C#和Python的Jupyter笔记本。这些笔记本演示了如何使用Semantic Kernel,并提供了可以一键运行的代码片段。
改进一下
# 导入内置的 `TextMemorySkill`。主要使用它的 `recall()`
text_memory_functions = kernel.import_skill(sk.core_skills.TextMemorySkill())
recall = text_memory_functions["recall"]
# 直接在代码里创建 semantic function。真实工程不建议这么做
sk_prompt = """
基于下面的背景信息回答问题。如果背景信息为空,或者和问题不相关,请回答"我不知道"。
[背景信息开始]
{{$input}}
[背景信息结束]
问题:{{$user_input}}
回答:
"""
ask = kernel.create_semantic_function(sk_prompt)
# 准备 context
context = kernel.create_new_context()
context[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "sk"
context[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = 0.8
context["input"] = "怎么使用 Semantic Kernel"
context["user_input"] = "怎么使用 Semantic Kernel"
# pipeline
result = await kernel.run_async(recall, ask, input_context=context)
print(result)
使用Semantic Kernel的最快方法是使用C#和Python的Jupyter笔记本。这些笔记本演示了如何使用Semantic Kernel,并提供了可以一键运行的代码片段。
Planner
SK 的 planner 概念上对标 LangChain 的 agent,但做得比较简单,还比较初步。
SK Python 提供了四种 planner:
1. SequentialPlanner
制定包含一系列步骤的计划,这些步骤通过自定义生成的输入和输出变量相互连接。更多参考 核心 prompt 和 官方例程
2. ActionPlanner
类似 OpenAI Function Calling,从 kernel 中已注册的所有 plugin 中找到一个该执行的函数。更多参考 核心 prompt 和 官方例程
3. StepwisePlanner
每执行完一步,都做一下复盘,只输出 action,不执行。更多参考 核心 prompt
4. BasicPlanner
不建议使用。把任务拆解,自动调用各个函数,完成任务。它只是个用于基础验证的功能,最终会被 SequentialPlanner 替代。更多参考 核心 prompt
planner 的使用步骤:
- 把 plugin 注册到 kernel
- 把 kernel 当参数实例化某个 planner
- 调用 planner 的
create_plan_async()方法获得 plan - 调用 plan 的
invoke_async()方法执行 plan
planner 接口并不一致,不能简单平替。
from semantic_kernel.core_skills import WebSearchEngineSkill
from semantic_kernel.connectors.search_engine import BingConnector
from semantic_kernel.planning import SequentialPlanner
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
import os
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 创建 semantic kernel
kernel = sk.Kernel()
# 配置 OpenAI 服务
api_key = os.getenv('OPENAI_API_KEY')
endpoint = os.getenv('OPENAI_API_BASE')
model = OpenAIChatCompletion(
"gpt-3.5-turbo", api_key, endpoint=endpoint)
# 把 LLM 服务加入 kernel
# 可以加多个。第一个加入的会被默认使用,非默认的要被指定使用
kernel.add_text_completion_service("my-gpt4", model)
# 导入搜索 plugin
connector = BingConnector(api_key=os.getenv("BING_API_KEY"))
kernel.import_skill(WebSearchEngineSkill(connector), "WebSearch")
sk_prompt = """
以下内容里出现的第一个日期是星期几?只输出星期几
{{$input}}
"""
kernel.create_semantic_function(
sk_prompt, "DayOfWeek", "DatePlugin", "输出 input 中出现的第一个日期是星期几")
# 创建 planner
planner = SequentialPlanner(kernel)
# 开始
ask = "周杰伦的生日是星期几?"
plan = await planner.create_plan_async(goal=ask)
result = await plan.invoke_async()
# 打印步骤用来调试
for index, step in enumerate(plan._steps):
print("Step:", index)
print("Description:", step.description)
print("Function:", step.skill_name + "." + step._function.name)
print("---")
if len(step._outputs) > 0:
print("Output:", str.replace(result[step._outputs[0]], "\n", "\n "))
print("---\n")
print(result)
Step: 0 Description: Performs a web search for a given query Function: WebSearch.searchAsync --- Output: ['关注. 展开全部. 阳历1979年1月18日星期四 农历 己未年 农历12月20日 姓名:周杰伦 英文名:Jay chou 出生:1979年1月18日 学历:淡江中学音乐科 生肖:马 血型:O型 星座:魔羯座 身高:175cm 体重:60kg 专长:写歌、作词、打球 专精乐器:钢琴、大提琴、吉他 ...'] Step: 1 Description: 输出 input 中出现的第一个日期是星期几 Function: DatePlugin.DayOfWeek --- Output: 星期四 --- 星期四
